드롭아웃
- 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서 (즉, 뉴런의 출력을 0으로 만들어) 과대적합을 막는다.
- 뉴런은 랜덤하게 드롭아웃되고 얼마나 많은 뉴런을 드롭할지는 우리가 정해야 할 또 다른 하이퍼파라미터
- 드롭아웃이 과대적합을 막는 이유?
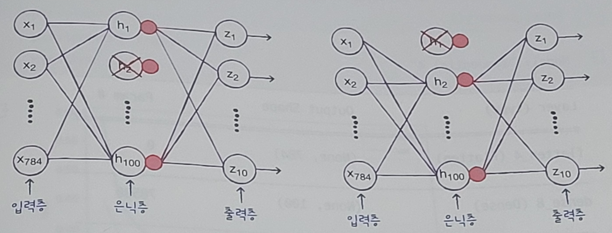
- 일부 뉴런이 랜던하게 꺼지면 특정 뉴런에 과대하게 의존하는 것을 줄일 수 있고 모든 입력에 대해 주의를 기울인다.
- 일부 뉴런의 출력이 없을 수 있다는 것을 감안하면 이 신경망은 더 안정적인 예측을 만들 수 있다.
- 아래의 2개의 신경망 그림을 보면 드롭아웃을 적용해 훈련하는 것이 2개의 앙상블을 하는 것처럼 보인다.
- 어떤 층의 뒷에 드롭아웃을 두어 이 층의 출력을 랜덤하게 '0'으로 생성
In [6]:
import tensorflow as tf
from tensorflow import keras
from tensorflow import keras
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
train_scaled = train_input/255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu', name='hidden'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
return model
In [7]:
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
hidden (Dense) (None, 100) 78500
dropout_1 (Dropout) (None, 100) 0
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
- 은닉층 뒤에 추가된 드롭아웃 층은 훈련되는 모델 파라미터가 없다.
- 입력과 출력의 크기가 같다.
- 훈련이 끝난 뒤에 평가나 예측을 수행할 때는 드롭아웃을 적용하지 말아야 한다.
- 훈련된 모든 뉴런을 사용해야 올바른 예측 수행 => 모델을 훈련한 다음 층을 다시 빼야 할까요?
- 아닙니다. 똑똑하게도 tensorflow & keras는 모델을 평가와 예측에 사용할 때는 자동으로 드롭아웃을 적용하지 않는다.
In [8]:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
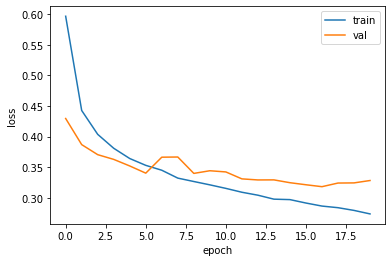
- 과대적합이 확실히 줄었다.
- 검증 손실의 감소가 멈추지만 크게 상승하지 않고 어느 정도 유지.
- 16번째부터 다시 과대적합으로 진행 => 다시 에포크 횟수를 지정 후, 모델 훈련 필요.
'책[이해 및 학습]' 카테고리의 다른 글
| 10. [혼자 공부하는 머신러닝/딥러닝] 콜백(callback) (0) | 2024.03.09 |
|---|---|
| 9. [혼자 공부하는 머신러닝/딥러닝] 모델 저장과 복원 (0) | 2024.03.09 |
| 7. [혼자 공부하는 머신러닝/딥러닝] 신경망 모델 훈련 (0) | 2024.03.09 |
| 6. [혼자 공부하는 머신러닝/딥러닝] 옵티마이저 (0) | 2024.03.09 |
| 5. [혼자 공부하는 머신러닝/딥러닝] 렐루함수 & Flatten layer (0) | 2024.03.09 |



