하이퍼파리미터
- 모델이 학습하지 않아 사람이 지정해 주어야 하는 파라미터
- 각종 하이퍼파라미터의 최적값을 찾는 것은 어려운 일이다.
- 신경망에는 특히 하이퍼파라미터가 많다.
- 은닉층의 개수
- 은닉층의 뉴런 개수
- 활성화 함수
- 층의 종류
- 미니배치 개수(batch_size 매개변수)
- epochs 반복 횟수
- compile() 메서드: 케라스의 기본 경사 하강법 알고리즘(RMSprop)
- 다양한 종류의 경사 하강법 알고리즘 제공 ==> 옵티마이저
- 가장 기본적인 옵티마이저 ==> 확률적 경사 하강법 SGD(기본적으로 미니배치)
- 알고리즘의 학습률
옵티마이저
- 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법
- 다양한 경사 하강법 알고리즘 존재
- SGD
- 네스테로프 모멘텀
- RMSprop
- Adam
옵티마이저 사용법
- model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
- 'sgd' 문자열을 기본 설정 매개변수로 인식
- sgd = keras.optimizers.SGD()
- model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
- 학습률 변경: sgd = keras.optimizers.SGD(learning_rate=0.1)
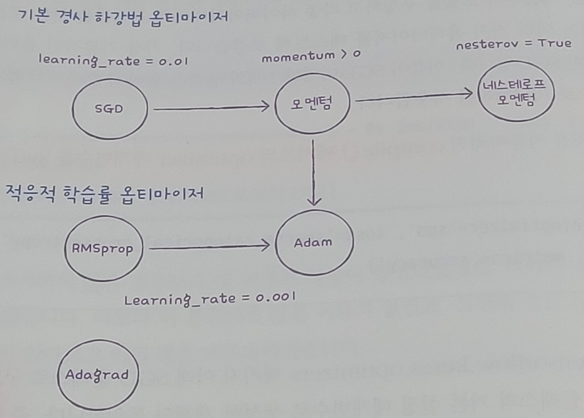
기본 경사 하강법 옵티마이저
- SGD 클래스에서 제공
- momentum 매개변수의 기본값: 0
- 모멘텀 최적화: 매개변수 값을 0보다 큰 값 지정 => 그레디언트를 가속도처럼 사용
- 네스테로프 모멘텀 최적화: nesterov 매개변수(False -> True)
- 모멘텀 최적화를 2번 반복하여 구현
- 대부분의 경우 네스테로프 모멘텀 최적화가 기본 확률적 경사 하강법보다 더 나은 성능 제공
적응적 학습률 옵티마이저
- 모델이 최적점에 가까이 갈수록 학습률을 낮출수 있다. => 안정적으로 최적점에 수렴할 가능성이 높다.
- 학습률 매개변수를 튜닝하는 수고를 덜 수 있다.
- Adagrad
- 그레디언트 제곱을 누적하여 학습률을 나눕니다.
- RMSprop
- Adagrad와 비슷하나, 최근의 그레디언트를 사용하기 위해 지수 감소를 사용
- Adam
- 모멘텀 최적화 + RMSprop 장점 접목
- learning_rate 기본값: 0.001
적응적 학습률 옵티마이저 [Adam] 사용
In [2]:
import tensorflow as tf
from tensorflow import keras
from tensorflow import keras
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
train_scaled = train_input/255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model = keras.Sequential(name='MNIST_model')
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu', name='hidden'))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
model.summary()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Model: "MNIST_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
hidden (Dense) (None, 100) 78500
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
Epoch 1/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.5301 - accuracy: 0.8154
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3977 - accuracy: 0.8574
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3577 - accuracy: 0.8705
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3297 - accuracy: 0.8785
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3120 - accuracy: 0.8860
Out[2]:
<keras.callbacks.History at 0x1ad4de0ef88>In [3]:
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 1s 1ms/step - loss: 0.3354 - accuracy: 0.8782
Out[3]:
[0.3353709578514099, 0.878166675567627]'책[이해 및 학습]' 카테고리의 다른 글
| 8. [혼자 공부하는 머신러닝/딥러닝] 드롭아웃 (0) | 2024.03.09 |
|---|---|
| 7. [혼자 공부하는 머신러닝/딥러닝] 신경망 모델 훈련 (0) | 2024.03.09 |
| 5. [혼자 공부하는 머신러닝/딥러닝] 렐루함수 & Flatten layer (0) | 2024.03.09 |
| 4. [혼자 공부하는 머신러닝/딥러닝] 층을 추가하는 방법(add 메서드) (0) | 2024.03.09 |
| 2. [혼자 공부하는 머신러닝/딥러닝] 인공 신경망(ANN) (0) | 2024.03.09 |


