기존에 사용하는 activation 함수
In [10]:
import tensorflow as tf
from tensorflow import keras
from tensorflow import keras
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
train_scaled = train_input/255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model = keras.Sequential(name='MNIST_model')
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Model: "MNIST_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden (Dense) (None, 100) 78500
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
Epoch 1/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.5614 - accuracy: 0.8097
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4090 - accuracy: 0.8536
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3723 - accuracy: 0.8647
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3503 - accuracy: 0.8737
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3329 - accuracy: 0.8796
Out[10]:
<keras.callbacks.History at 0x1e4d9b00ec8>시그모이드 함수 단점
- 오른쪽과 왼쪽 끝으로 갈수록 그래프가 누워있기에 올바른 출력을 만드는 데 빠르지 못함.
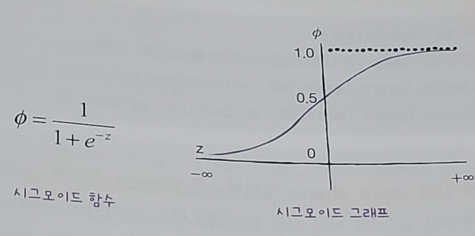
- 층이 많은 심층 신경망일수록 그 효과가 누적되어 학습을 더 어렵게 만듬.
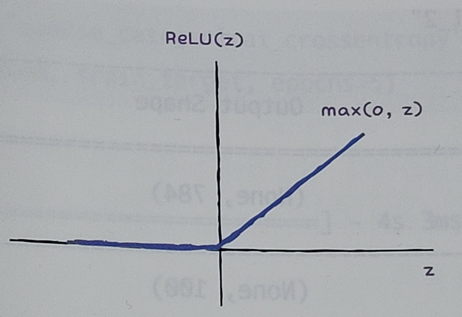
- 이러한 개선점으로 렐루함수가 등장.
- 입력이 양수일 경우 마치 활성화 함수가 없는 것처럼 그냥 입력 통과
- 음수일 경우에는 '0'으로 만듬.
- 특히 이미지 처리에서 좋은 성능을 낸다고 알려짐.
패션 MNIST 데이터(28 x 28)이기에 인공 신경망에 주입하기 위해 넘파이 배열 reshape() 메서드 사용
케라스에서는 데이터의 크기 변경을 위해 Flatten층을 제공 ==> 즉, reshape() 대체
- 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할만 수행
- 입력에 곱해지는 가중치나 절편이 없음.
- 입력층과 은닉층 사이에 추가하기에 이를 층으로 부름.
- 입력값의 차원을 짐작할 수 있어 큰 장점
- 입력데이터에 대한 전처리 과정을 가능한 모델에 포함시키는 것이 룰
In [7]:
import tensorflow as tf
from tensorflow import keras
from tensorflow import keras
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
train_scaled = train_input/255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model = keras.Sequential(name='MNIST_model')
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu', name='hidden'))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
model.summary()
Model: "MNIST_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_3 (Flatten) (None, 784) 0
hidden (Dense) (None, 100) 78500
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
모델 훈련
In [8]:
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.5339 - accuracy: 0.8125
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3933 - accuracy: 0.8572
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3549 - accuracy: 0.8723
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3337 - accuracy: 0.8819
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3185 - accuracy: 0.8846
Out[8]:
<keras.callbacks.History at 0x1e4d7574a48>검증 세트에서 확인
In [9]:
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 1s 1ms/step - loss: 0.3620 - accuracy: 0.8742
Out[9]:
[0.3620034456253052, 0.8741666674613953]'책[이해 및 학습]' 카테고리의 다른 글
| 7. [혼자 공부하는 머신러닝/딥러닝] 신경망 모델 훈련 (0) | 2024.03.09 |
|---|---|
| 6. [혼자 공부하는 머신러닝/딥러닝] 옵티마이저 (0) | 2024.03.09 |
| 4. [혼자 공부하는 머신러닝/딥러닝] 층을 추가하는 방법(add 메서드) (0) | 2024.03.09 |
| 2. [혼자 공부하는 머신러닝/딥러닝] 인공 신경망(ANN) (0) | 2024.03.09 |
| 1. [혼자 공부하는 머신러닝/딥러닝] 로지스틱 회귀로 분석 (0) | 2024.03.09 |


