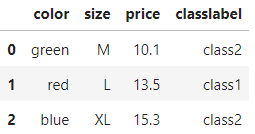
import pandas as pd
df = pd.DataFrame([['green', 'M', 10.1, 'class2'],
['red', 'L', 13.5, 'class1'],
['blue', 'XL', 15.3, 'class2']])
df.columns = ['color', 'size', 'price', 'classlabel']
df
순서가 있는 특성 매핑
1) 학습 알고리즘이 순서 특성을 올바르게 인식하려면, 범주형의 문자열 값 ==> 정수로 변환
2) 매핑 함수를 직접 만들어야 한다.
In [3]:
size_mapping = {'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
df
나중에 정수값을 다시 원래 문자열 표현으로 변경 ==> 거꾸로 매핑하는 딕셔너리
In [4]:
inv_size_mapping = {v:k for k, v in size_mapping.items()}
print(inv_size_mapping)
df['size'].map(inv_size_mapping)
print(df)
df['size'] = df['size'].map(inv_size_mapping)
df{3: 'XL', 2: 'L', 1: 'M'}
color size price classlabel
0 green 1 10.1 class2
1 red 2 13.5 class1
2 blue 3 15.3 class2
클래스 레이블 인코딩
1) enumerate 이용: 반복 가능한 객체(문자열,리스트,넘파이배열) 입력으로 받아 인덱스와 값의 튜플을 차례로 반환.
In [5]:
import numpy as np
class_mapping = {label:idx for idx, label in enumerate(np.unique(df['classlabel']))}
class_mapping
df['classlabel'] = df['classlabel'].map(class_mapping)
df
나중에 정수값을 다시 원래 문자열 표현으로 변경 ==> 거꾸로 매핑하는 딕셔너리
In [6]:
inv_class_mapping = {v:k for k,v in class_mapping.items()}
df['classlabel'] = df['classlabel'].map(inv_class_mapping)
df
사이킷런에 구현된 LabelEncoder 클래스를 사용
1) fit_transform: fit 메서드 + transform 메서드
2) inverse_transform: 정수 클래스 레이블 ==> 원본 문자열
In [7]:
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y = class_le.fit_transform(df['classlabel'])
print(y)
inverse = class_le.inverse_transform(y)
print(inverse)
[1 0 1]
['class2' 'class1' 'class2']
순서가 없는 특성에 원-핫 인코딩 적용
1) LabelEncoder: 입력 데이터로 1차원 배열을 기대
2) 데이터셋에 변경해야 할 열이 많다면 ==> OrdinalEncoder & ColumnTransformer 을 이용하면 여러 개의 열을 한번에 정수로 변환 가능
3) 정수로 인코딩된 값을 다시 문자열로 변환 ==> namedtransformers
In [8]:
x = df[['color', 'size', 'price' ]].values
color_le = LabelEncoder()
x[:,0] = color_le.fit_transform(x[:,0])
print(x)
[[1 'M' 10.1]
[2 'L' 13.5]
[0 'XL' 15.3]]
from sklearn.preprocessing import OrdinalEncoder
from sklearn.compose import ColumnTransformer
ord_enc = OrdinalEncoder(dtype=np.int) ## np.int error 발생 이유: 실수값이 포함.
x = ord_enc.fit_transform(df)
print(x)
## 변경하고자하는 열의 리스트
## ColumnTransformer(트랜스포머의 이름, 변환기, 변환할 열의 리스트)
col_trans = ColumnTransformer([('ord_enc', ord_enc, ['color', 'size', 'classlabel'])])
x_trans = col_trans.fit_transform(df)
print(x_trans)
## 정수로 인코딩된 값을 다시 문자열로 변환
col_trans.named_transformers_['ord_enc'].inverse_transform(x_trans)
[[1 1 0 1]
[2 0 1 0]
[0 2 2 1]]
[[1 1 1]
[2 0 0]
[0 2 1]]
C:\Users\sel04327\AppData\Local\Temp\ipykernel_166048\3538419393.py:3: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
ord_enc = OrdinalEncoder(dtype=np.int) ## np.int error 발생 이유: 실수값이 포함.
Out[9]:
array([['green', 'M', 'class2'],
['red', 'L', 'class1'],
['blue', 'XL', 'class2']], dtype=object)
원-핫 인코딩(one-hot encoding)
1) 원-핫 인코딩: 한 개의 요소는 True, 나머지 요소는 False로 만들어 주는 기법
2) 원-핫 인코딩 필요한 이유
- scikit-learn에서 제공하는 머신러닝 알고리즘은 문자열 값을 입력 값으로 허락하지 않기 때문에 모든 문자열 값들을 숫자형으로 인코딩하는 전처리 작업(Preprocessing) 후에 머신러닝 모델에 학습
- a = 1, b = 2, c = 3으로 한 컬럼에 각기 다른 숫자형 데이터로 변경한 후,이 데이터 값을 머신러닝 알고리즘에 그대로 넣어 데이터를 예측 하라고 지시한다면 컴퓨터가 이들 값의 관계를 예상과 다르게 형성할 가능성이 있다.
- a, b, c 각각이 관련이 없는 값임에도 불구하고 1 + 2 = 3 ==> a + b = c와 같은 잘못된 관계를 형성 가능성 존재함.
In [11]:
from sklearn.preprocessing import OneHotEncoder
x = df[['color', 'size', 'price']].values
color_ohe = OneHotEncoder()
color_ohe.fit_transform(x[:, 0].reshape(-1, 1)).toarray()
Out[11]:
array([[0., 1., 0.],
[0., 0., 1.],
[1., 0., 0.]])
1) reshape method.


2) 여러 개의 특성이 있는 배열에서 특정 열만 변환: ColumnTransformer
In [13]:
from sklearn.compose import ColumnTransformer
x = df[['color', 'size', 'price']].values
c_transf = ColumnTransformer([('onehot', OneHotEncoder(), [0]), ('nothing', 'passthrough', [1, 2])])
c_transf.fit_transform(x)
Out[13]:
array([[0.0, 1.0, 0.0, 'M', 10.1],
[0.0, 0.0, 1.0, 'L', 13.5],
[1.0, 0.0, 0.0, 'XL', 15.3]], dtype=object)3) 판다스의 get_dummies 메서드 사용
- 문자열 열만 변환하고 나머지 열은 그대로 둔다.
In [16]:
pd.get_dummies(df[['price', 'size', 'color']])
## 변환하려는 특성을 구체적으로 지정.
pd.get_dummies(df[['price', 'size', 'color']], columns=['size'])
'Machine Learning with Python' 카테고리의 다른 글
| 04_Data preprocessing: 누락된 데이터 다루기(숫자) (0) | 2023.01.01 |
|---|---|
| 03_Data preprocessing: 특성 스케일 맞추기 (0) | 2022.12.20 |
| 02_머신러닝 with 분류모델(k-neighbor) (0) | 2022.12.02 |
| 01_머신 러닝 개념 (0) | 2022.12.02 |
| 3-3-B_규제(regularization) (0) | 2022.08.23 |



